サイオスコーポレートブログ
-

カルチャー2026年4月 1日
2026年4月1日、サイオスグループは21名の新入社員を迎えました。新入社員に対する代表取締役社長 喜多伸夫のメッセージをご紹介します。
-

製品・サービス2026年3月16日
2026年2月18日、サイオスグループは事業戦略発表会をオンラインで開催し、中長期的な企業価値向上と持続的な成長に向けた戦略を発表しました。本稿ではその概要をお伝えします。
-

カルチャー2026年2月19日
アーキタイプベンチャーズ福井氏に聞く、B2B Techの最新トレンドとAI時代の開発手法
2026年1月20日、サイオスグループは新年のスタートを飾るキックオフミーティングを開催。独立系VCアーキタイプベンチャーズの福井俊平氏をお招きし、最新の投資動向やB2B領域のビジネス環境など、ITビジネスの未来について当社経営陣と語り合った対談の様子をお届けします。
-

製品・サービス2025年12月23日
LifeKeeper v10 ローンチイベント「新章披露の宴」を開催
HAクラスターソフトウェア「LifeKeeper v10」の提供開始に合わせて2025年11月19日、進化したコンセプトやデザイン・機能などを発表するイベントが観世能楽堂で開催されました。LifeKeeperがこれまで築き、守り、継承・継続してきたものと今後の展望についてお伝えします。
-

カルチャー2025年4月 1日
2025年4月1日、サイオスグループは15名の新入社員を迎えました。新入社員に対する代表取締役社長 喜多伸夫のメッセージをご紹介します。
-

製品・サービス2025年3月13日
2025年2月26日、サイオスグループは事業戦略発表会をオンラインで開催し、中期経営計画に基づく2025年度の成長戦略を発表しました。本稿ではその概要をお伝えします。
-

カルチャー2025年1月14日
米国事業会社でのハッカソン体験記―― 目標に向かって相互に支援する企業文化に触れる #2
米国事業会社 SIOS Technology Corp.が開催するハッカソンに参加したサイオステクノロジーの若手エンジニア2名。彼らがハッカソンに参加した動機やきっかけ、ハッカソンを通じてどのような学びや気づきを得られたのか、今後どのようなことにチャレンジしたいのか尋ねました。
-

カルチャー2025年1月 8日
米国事業会社でのハッカソン体験記―― 目標に向かって相互に支援する企業文化に触れる #1
HAクラスターソフトウェア「LifeKeeper」を開発する米国事業会社 SIOS Technology Corp.は2024年7月、社内のエンジニアを対象としたハッカソンを開催しました。サイオステクノロジーから参加したエンジニアにハッカソンの概要や取り組んだテーマについて聞きました。
-

カルチャー2024年12月 4日
米国事業会社SIOS Technology Corp.(STC)で、ハイアベイラビリティ(高可用性)ソリューションの開発に携わるエディー・ウィリアムズ(Eddie Williams)さんとブレット・バーウィック(Brett Barwick)さんにSTCの魅力を尋ねました。
-

カルチャー2024年11月20日
米国事業会社SIOS Technology Corp.(STC)で、ハイアベイラビリティ(高可用性)ソリューションの開発に携わるエディー・ウィリアムズ(Eddie Williams)さんとブレット・バーウィック(Brett Barwick)さんに、STCでの働きがいを尋ねました。
-

製品・サービス2024年11月11日
クラウドワークフロー「Gluegent Flow」、新機能発表・デモ体験会を開催
サイオステクノロジーは2024年10月16日、生成AIを活用した「ユーザーアシスト」機能をクラウドワークフロー「Gluegent Flow(グルージェントフロー)」で提供開始することを発表しました。DXを阻む課題にどう対応するか、開発のねらいと新機能の概要、今後の展望をお伝えします。
-

カルチャー2024年8月27日
DataKeeperの「育ての親」、これからも世の中に貢献するソフトウェアを創り続ける #2
米国事業会社 SIOS Technology Corp.で、DataKeeperなどのソフトウェア開発で中心的役割を果たし、現在はアーキテクトを務めるアーニー・コスクレイ(Ernie Coskrey)さん。後編では、製品に対する思いや今後新たに挑戦したいことなどを尋ねました。
-

カルチャー2024年8月20日
DataKeeperの「育ての親」、これからも世の中に貢献するソフトウェアを創り続ける #1
米国事業会社 SIOS Technology Corp.で、DataKeeperなどのソフトウェア開発で中心的役割を果たし、現在はアーキテクトを務めるアーニー・コスクレイ(Ernie Coskrey)さん。これまでの歩みやSTCで働くきっかけについて伺いました。
-

テクノロジー2024年8月 6日
サイオステクノロジーとElasticsearch K.K. 日本における業務提携に関する共同発表会を開催 #2
サイオステクノロジーとElasticsearch K.K.が2024年7月に開催した共同発表会より、Elasticの日本市場における事業戦略やサイオステクノロジーとの業務提携に対する期待について、お伝えします。
-

テクノロジー2024年8月 1日
サイオステクノロジーとElasticsearch K.K. 日本における業務提携に関する共同発表会を開催 #1
サイオステクノロジーとElasticsearch K.K.が2024年7月に開催した共同発表会より、サイオステクノロジーの戦略的パートナーとしての思い、RAGへのElastic Search AI Platform適用で日本国内における生成AIの利活用促進への取り組みをお伝えします。
-

テクノロジー2024年6月25日
日本OSS推進フォーラムとIPAが「OSS利活用事例セミナー」を共同開催【後編】
2024年5月27日、日本OSS推進フォーラムは、情報処理推進機構(IPA)と共催でセミナーを開催しました。テーマは、ビジネスをソフトウェアの力でどう変革するか。価値の創造や事業の変革に取り組む企業の事例を通じて、イノベーションの具体的なヒントを探りました。こちらのレポートの後編です。
-

テクノロジー2024年6月19日
日本OSS推進フォーラムとIPAが「OSS利活用事例セミナー」を共同開催【前編】
2024年5月27日、日本OSS推進フォーラムは、情報処理推進機構(IPA)と共催でセミナーを開催しました。テーマは、ビジネスをソフトウェアの力でどう変革するか。価値の創造や事業の変革に取り組む企業の事例を通じて、イノベーションの具体的なヒントを探りました。
-

カルチャー2024年4月17日
魅力的なサービスを提供し続けるために――仲間たちとともに切り拓く未来 #2
米国事業会社SIOS Technology Corp.で、カスタマーエクスペリエンスのvice presidentを務めるカシウス・ルー(Cassius Rhue)さん。より良い職場づくりのために心がけていることや今後のビジョンについて伺いました。
-

カルチャー2024年4月 2日
2024年4月1日、サイオスグループは18名の新入社員を迎えました。新入社員に対する代表取締役社長 喜多伸夫のメッセージをご紹介します。
-

カルチャー2024年3月27日
魅力的なサービスを提供し続けるために――仲間たちとともに切り拓く未来 #1
米国事業会社SIOS Technology Corp.で、LifeKeeperなどのソフトウェア製品開発に23年以上携わり、現在はカスタマーエクスペリエンスのvice presidentを務めるカシウス・ルー(Cassius Rhue)さん。長く働くモチベーションの源泉を訊きました。
-

製品・サービス2024年3月13日
2024年2月13日、サイオスグループは事業戦略発表会をオンラインで開催し、2023年度の事業進捗と2024年度の注力事業を発表しました。本稿では、注力事業のSaaS事業、APIソリューション事業などサイオスグループの最新動向と今後の展望について、お伝えします。
-

カルチャー2024年2月27日
2024年賀詞交歓会を開催、デジタル技術がもたらす未来を考える
2024年1月23日、サイオスグループの賀詞交歓会がオンラインで開催されました。第一部でデジタル大臣政務官 兼 内閣府大臣政務官 衆議院議員 土田慎様の基調講演、第二部でパネルディスカッションを行いました。
-

カルチャー2024年1月23日
米国事業会社SIOS Technology Corp.で、エンジニアリング部門のvice presidentを務めるサジド・シェイク(Sajid Shaikh)さん。4人の子どもを育てる父として、夫として、また仕事や家庭と両立して学ぶ大学院生として、日々心がけていることを尋ねました。
-

カルチャー2024年1月11日
米国事業会社SIOS Technology Corp.で、エンジニアリング部門のvice presidentを務めるサジド・シェイク(Sajid Shaikh)さん。仕事も家族も大好きと語るサジドさんに、ワークライフバランスを保つ秘訣を尋ねました。
-

カルチャー2023年9月 4日
味方を見つけること、誰かの味方になること――より自分らしく生きるために #2
米国事業会社SIOS Technology Corp.で、プロダクトマネジメントのディレクターを務めるエイドリアン・クーリー(Adrienne Cooley)さん。キャリアにおいて重要な「Ally」や経験を重ねるなかでの気づきについて伺いました。
-

カルチャー2023年8月28日
味方を見つけること、誰かの味方になること――より自分らしく生きるために #1
米国事業会社SIOS Technology Corp.で、プロダクトマネジメントのディレクターを務めるエイドリアン・クーリー(Adrienne Cooley)さん。ソフトウェアエンジニアとしての歩み、そして誰もがいきいきと働ける多様な組織や社会をつくるためにできることを聞きました。
-

カルチャー2023年7月12日
お互いを理解し、助け合うことの大切さ――キャリアから得た、私の気づき #2
米国事業会社SIOS Technology Corp.にはお互いを尊重しあう文化がある、と語るセールスとマーケティング部門のvice presidentを務めるマーガレットさん。その理由を尋ねるとともに、今後のチャレンジについても伺いました。
-

カルチャー2023年6月28日
お互いを理解し、助け合うことの大切さ――キャリアから得た、私の気づき #1
米国事業会社SIOS Technology Corp.のセールスとマーケティング部門のvice presidentを務めるマーガレット・ホーグランド(Margaret Hoagland)さん。これまで歩んできたキャリアと仕事をするうえで大切にしていることを聞きました。
-

製品・サービス2023年3月 3日
LifeKeeper PARTNER SUMMIT 2023を開催
2023年2月9日、LifeKeeper PARTNER SUMMIT 2023が虎ノ門ヒルズフォーラムにて開催されました。LifeKeeperの販売パートナー各社をお招きし、2023年度に進める戦略をご説明するとともに、ビジネスエコシステムの進展に向けた協業を呼びかけました。
-

カルチャー2023年2月20日
2023年1月24日、サイオスグループ社員が参加する賀詞交歓会がオンラインで開催されました。基調講演には、シスコシステムズ合同会社の代表執行役員社長 中川いち朗様をお招きし、働きがいあふれる同社の職場づくりのポイントを伺いました。
-

製品・サービス2023年1月17日
顧客のDX推進を支援するSaaSを成長軌道へ サイオスグループ事業戦略発表会を開催 #2
2022年12月7日、サイオスグループは事業戦略発表会をオンラインで開催しました。注力分野であるSaaS事業について、サイオステクノロジー株式会社 SaaSビジネス ストラテジストの瀧下浩が解説、サイオス株式会社 代表取締役社長の喜多伸夫がその思いを述べました。
-

製品・サービス2022年12月27日
顧客のDX推進を支援するSaaSを成長軌道へ サイオスグループ事業戦略発表会を開催 #1
2022年12月7日、サイオスグループは事業戦略発表会をオンラインで開催しました。サイオス株式会社 代表取締役社長の喜多伸夫とサイオステクノロジー株式会社 SaaSビジネス ストラテジストの瀧下浩が登壇し、注力分野であるSaaS事業を中心発表を行いました。
-

カルチャー2022年12月12日
米国事業会社SIOS Technology Corp.で人事全般をとりまとめるHead of People and Cultureを務めている坂本真琴さんに話を聞く今回のインタビュー。最終回は、大病の経験をきっかけに得た気づきについて聞きました。
-
カルチャー2022年12月 5日
米国事業会社SIOS Technology Corp.で人事全般をとりまとめる「Head of People and Culture」を務めている坂本真琴さん。今回は坂本さんがHuman Resourceすなわち人材に関わる仕事に取り組むきっかけとなった出来事について聞きました。
-
カルチャー2022年11月21日
米国事業会社SIOS Technology Corp.は「Best Places To Work in South Carolina」を3年連続で受賞。人事全般を担当する坂本真琴さんに、どのような取り組みが実を結んできたのか話を聞きました。
-
カルチャー2022年11月15日
米国事業会社SIOS Technology Corp.で人事全般を担当する坂本真琴さんは、この10年ほどで社員の意識に変化がみられると語ります。キーワードは「belonging」。同じ組織に属する誇れる仲間と仕事をする一体感や安心感を意味する言葉です。これまでの取り組みを聞きました。
-

テクノロジー2022年8月24日
2022年7月15日、日本OSS推進フォーラムの「Web3 ワーキンググループ」第1回勉強会がオンラインで開催されました。ブロックチェーン技術を用いた次世代ウェブとして注目される「Web3(ウェブスリー)」は、私たちにどのような世界をもたらすのでしょうか。
-

テクノロジー2022年7月29日
精神科病院向け電子カルテサービス「INDIGO NOTE」の特長を紹介
2022年7月2日に開催された「第26回日本医療情報学会春季学術大会」。そのセッションの中でサイオステクノロジーは、次世代医療情報交換規約「HL7 FHIR」を採用した精神科病院向け電子カルテサービス「INDIGO NOTE(インディゴノート)」を紹介しました。
-

テクノロジー2022年7月 8日
2022年6月24日、JAPANSecuritySummit Update 編集部主催のウェビナーにてサイオステクノロジー上席執行役員情報セキュリティ担当 面和毅(おも かずき)が、2022年上期におけるインシデントと脆弱性の動向、今後の対策などを解説しました。
-
テクノロジー2022年2月25日
Developers Summit 2022 対談セッション OSSの文化を未来に伝える
IT技術者やクリエイターの祭典Developers Summit(主催:株式会社翔泳社CodeZine編集部)にて、サイオステクノロジー上席執行役員 黒坂肇とFRAME00 CTO Aggre氏が、OSSの過去・現在・未来について語りました。
-
カルチャー2022年2月 4日
2022年賀詞交歓会、SIOS Value Award年間賞を発表
2022年1月19日、サイオスグループの賀詞交歓会がオンラインで開催されました。代表取締役社長 喜多伸夫のキックオフコメントに続き、SIOS Value Award年間賞が発表されました。
-
ピープル2022年1月21日
パネルディスカッション・レポート 【オンライン就活を語る!】学生の就活現状・課題、学校・先生の支援について
2021年12月3日、大学と高等専門学校の先生3名をお招きし、パネルディスカッションを開催。オンラインでの授業や就活の現状、学ぶ側・教える側の悩みや課題解決に向けた取り組み等が話題に上りました。実りある学生生活や就職活動、大学運営における課題解決のヒントになれば幸いです。
-

カルチャー2021年12月24日
2022年度サイオスグループの事業戦略 お客様に価値を感じ続けてもらうサービス(SaaS)を育む
2021年12月8日、サイオスグループの事業戦略発表会がオンライン開催されました。本レポートでは2022年度における事業戦略の要旨を、サイオステクノロジー 上席執行役員SaaSビジネスストラテジストの瀧下浩がBtoB向けに開発・提供するSaaS事業の取り組みを中心に説明しました。
-

カルチャー2021年12月17日
2022年5⽉に迎える設⽴25周年 サイオスグループの事業戦略と新コーポレートロゴを発表
2021年12⽉8⽇、サイオスグループの事業戦略発表会がオンライン開催されました。2022年5⽉に控えた設⽴25周年に先⽴ってサイオス株式会社代表取締役社⻑の喜多伸夫がサイオスグループのこれまでの歩みと今後の事業戦略、新たなコーポレートロゴマークに込めた思いを述べました。
-

テクノロジー2021年12月16日
第19回北東アジアOSS推進フォーラム 日本OSS推進フォーラム理事長としてサイオステクノロジー上席執行役員の黒坂肇が活動報告
2021年12月3日、第19回北東アジアOSS推進フォーラムがオンラインで開催されました。日本OSS推進フォーラム理事長を務めるサイオステクノロジー上席執行役員の黒坂肇が、企業の課題解決や産業界のDXにおけるOSS(オープンソースソフトウェア)の重要性を指摘しました。
-

テクノロジー2021年12月10日
SIerが考えるべき新たなビジネスモデル「レガシーSIからの脱却」
日本のSI(システムインテグレーション)業界でみられる共通の課題、そして解決の道筋とは――。BCN Conference 2021 秋 オンラインのセッションで、日本OSS推進フォーラムの理事長などを務めるサイオステクノロジー上席執行役員の黒坂肇が当社の取り組みを交えながら語りました。
-

テクノロジー2021年10月29日
The Open Groupの創立25周年イベントで代表取締役社長 喜多伸夫がスピーチ 時代をリードする標準の提案と普及活動に期待
2021年10月26日(CST)から27日(EDT)にかけて、The Open Groupの創立25周年イベントがオンラインで開催されました。同グループのグローバル会員であるサイオスでは、代表取締役社長 喜多伸夫が活動を振り返るとともに、今後の期待を述べました。
-

ピープル2021年9月 3日
パネルディスカッション・レポート【メンタルヘルスケア】 オンライン授業が学生のメンタルに与える影響・課題・支援について
2021年6月22日、オンライン授業を導入する中央大学 国際情報学部 教授の飯尾(いいお)淳先生、聖徳大学 心理・福祉学部 社会福祉学科 講師の久米知代先生をお招きし、パネルディスカッションを開催しました。コロナ禍のさまざまな制約下で、新たな学びの姿を模索する大学の「今」を伺いました。
-

ピープル2021年8月17日
「つくること」と「支えること」が持続する未来のトークンエコノミー【後編】
世界で初めてとなる日本発の分散型プロトコルDev Protocolを通じて、クリエイターと支援者の双方が経済的価値を得られる仕組みを社会実装するFRAME00(フレームダブルオー)。対談の後編ではFRAME00起業の経緯、今後のチャレンジなどを伺いました。
-

ピープル2021年7月16日
「つくること」と「支えること」が持続する未来のトークンエコノミー【前編】
分散型プロトコルDev Protocolを開発したFRAME00(フレームダブルオー)のCEO(最高経営責任者)である原麻由美さん、CTO(最高技術責任者)のAggreさんをお招きし、サイオステクノロジー上席執行役員 黒坂肇とともに持続的なエコシステムの実現について語りました。
-

ピープル2021年1月27日
お客様の新事業やサービス構想をカタチにする基幹業務システムを開発、Financial & Unique SIサービスライン
2020年10月、組織再編によってサイオステクノロジーに新しいサービスラインが発足しました。その1つに「Financial & Unique SI サービスライン」があります。同サービスラインのキーパーソンに、サービスラインの強みや目指す組織の将来像を尋ねました。
-

ピープル2021年1月20日
大学オンライン授業に関する調査報告・討論会「文教領域デジタルトランスフォーメーション(DX)化の現状と今後の展望」
サイオステノクロジーではオンライン授業を導入した大学・大学院にヒアリング調査を実施。調査結果を交えながら、教育機関におけるDX化の課題や現場での取り組み、将来の展望などをお伝えするイベントを2020年12月4日に開催しました。遠隔授業をテーマとしたパネルディスカッションを振り返ります。
-

テクノロジー2020年9月28日
DX推進の鍵になる気鋭のサービスメッシュKumaをいち早くレビュー
2020年9月8日、オンライン開催されたCloudNative Days Tokyo 2020でサイオステクノロジー シニアアーキテクトの槌野雅敏が登壇。オープンソースのKumaに焦点を当て、モダナイズやDXの文脈で注目されるサービスメッシュの可能性を探りました。
-

ピープル2020年9月11日
サイオステクノロジーのシニアアーキテクトとして情報発信をする意義とは
2020年7月、サイオステクノロジーとして初の「Microsoft Most Valuable Professional (Microsoft MVP)」に選ばれたシニアアーキテクトの武井 宜行(たけい のりゆき)。技術者としての心がけや情報発信に力を入れる理由について聞きました。
-

テクノロジー2020年8月 7日
Virtual Azure Community Day 日本語トラックで「Azure Kubernetes Services活用事例」を解説
2020年7月28日に開催されたVirtual Azure Community Day。コミュニティに参加するAzureエキスパートが最新技術を解説する日本語トラックでは、サイオステクノロジーのシニアアーキテクトの1人、武井宜行(たけい のりゆき)がウェビナーに登壇しました。
-

ピープル2020年5月20日
営業一筋の戦略家。穏やかな笑顔の内に情熱を秘め、挑戦者であり続ける──サイオステクノロジー上席執行役員 下園 文崇
【サイオスグループ役員インタビュー】多彩な顔触れが揃うサイオスグループの経営陣。その人柄を通して、サイオスグループの魅力をお伝えするシリーズ企画。今回は、サイオステクノロジー株式会社 上席執行役員の下園文崇(しもぞの のりたか)を紹介します。
-

ピープル2020年4月27日
セキュリティ一筋に。フレキシブルな活躍で、メンバーを鼓舞する──サイオステクノロジー 上席執行役員 面 和毅
【サイオスグループ役員インタビュー】多彩な顔触れが揃うサイオスグループの経営陣。その人柄を通して、サイオスグループの魅力をお伝えするシリーズ企画。今回は、サイオステクノロジー株式会社 上席執行役員の面和毅(おも かずき)を紹介します。
-

ピープル2020年3月17日
事業の財産は、エンジニア。自社の価値を上げ、業界全体の発展を目指す──サイオステクノロジー 執行役員 黒坂 肇【後編】
【サイオスグループ役員インタビュー】前編記事では、サイオステクノロジー 執行役員 第2事業部 副事業部長の黒坂肇が経営面や人材育成の理念について述べました。続く後編では、リーダーシップ論や今後のビジョンに関する熱い思いを打ち明けました。
-

ピープル2020年3月11日
事業の財産は、エンジニア。自社の価値を上げ、業界全体の発展を目指す──サイオステクノロジー 執行役員 黒坂 肇【前編】
【サイオスグループ役員インタビュー】多彩な顔触れが揃うサイオスグループの経営陣。その人柄を通して、サイオスグループの魅力をお伝えするシリーズ企画。今回は、グループ内最古参のひとり、サイオステクノロジー 執行役員の黒坂肇に、自身が考える経営面や人材育成の理念について尋ねました。
-

製品・サービス2020年3月10日
三浦市社会福祉協議会 第4回「Willysm(ウィリズム)」利用者表彰式
三崎マグロで有名な神奈川県三浦市の社会福祉協議会は、キーポート・ソリューションズのモチベーション・マネジメントシステム 「Willysm(ウィリズム)」を導入して健康経営を実践しています。それを讃えて「Willysm」利用者最優秀賞を2020年1月に受賞されました。
-

製品・サービス2020年2月18日
「大塚商会実践ソリューションフェア2020」へ、サイオステクノロジーが複合機ソリューションを出展
「ITで拓く、働き方改革」をメインテーマに掲げた「大塚商会実践ソリューションフェア2020」に、今年もサイオステクノロジーの複合機ソリューション各種が出展しました。東京会場初日の様子をレポートします。
-

テクノロジー2019年12月16日
「サイオスOSSよろず相談室」ユーザーの集い「SOY倶楽部 ユーザー会2019」を開催
サイオステクノロジーは、OSSの活用を積極的に図る企業の皆さまの情報交換の場として、「SOY倶楽部ユーザー会2019」を開催しました。そのイベントの模様をレポートします。
-
.jpg)
テクノロジー2019年11月25日
「Red Hat Forum Tokyo 2019」にて、サイオステクノロジーが展示ブースとセッションを提供
2019年11月15日に開催された「Red Hat Forum Tokyo 2019」。サイオステクノロジーは、Red Hat OpenShift関連ソリューションのブースを出展し、AIOpsソリューション「Red Sky Ops」に関するセッションに登壇しました。
-

テクノロジー2019年11月 6日
APIエコノミーとサブスクリプションビジネスをテーマにメディア向けの勉強会を開催
サイオステクノロジーは、報道関係者向けにAPIエコノミー並びにサブスクリプションビジネスをテーマとする勉強会を開催しました。その模様をレポートします。
-

ピープル2019年10月 4日
信念を持ち、堅実に改善を積み重ねることに徹する──サイオス 執行役員 籔中 雄介
【サイオスグループ役員インタビュー】多彩な顔触れが揃うサイオスグループの経営陣。その人柄を通して、サイオスグループの魅力をお伝えするシリーズ企画。今回は、2019年4月にサイオスの執行役員に就任した管理統括本部 財務経理部長の籔中雄介を紹介します。
-

テクノロジー2019年9月 2日
あらゆるサブスクリプションビジネスのプラットフォームとなる画期的なサービス「SIOS bilink」~後編~
サブスクリプションビジネスをスタートする企業を後押しする「SIOS bilink(サイオス ビリンク)」の提供をサイオステクノロジーでは2019年6月に開始しました。前編に続き、そのコンセプトや特長について、開発担当のキーパーソンに話を聞きました。
-

テクノロジー2019年8月15日
セミナーイベント「サブスクリプションドライバー vol.1」を開催
2019年8月8日、サイオステクノロジーは、日本マイクロソフト品川本社(東京・港区)にて、「サブスクリプションドライバー vol.1」を開催しました。その概要をレポートします。
-

テクノロジー2019年8月 6日
あらゆるサブスクリプションビジネスのプラットフォームとなる画期的なサービス「SIOS bilink」~前編~
サイオステクノロジーは、サブスクリプションビジネスをスタートする企業を力強く後押しする新サービス「SIOS bilink(サイオス ビリンク)」の提供を開始しました。そのコンセプトと特長について、開発担当チームに話を聞きました。
-

テクノロジー2019年6月20日
国内最⼤級のカンファレンスAWS Summit Tokyo 2019にGold Sponsorとして出展──AWSの安定運用を担保するSIOSソリューションを紹介
2019年6月12日~14日の3日間にわたり、幕張メッセ(千葉・千葉市)でAWS Summit Tokyo 2019が開催されました。サイオステクノロジーは展示ブースへの出展に加え、可用性を高めるAWS運用事例をテーマにセッションを提供。その模様をレポートします。
-

テクノロジー2019年3月20日
大学や高度研究機関に不可欠なユーザー認証基盤と、マイクロソフトの認証サービスを連携させるインテグレーションサービスを提供
サイオステクノロジーは、数多くの大学・高等教育機関のご要望に応える認証基盤の導入を支援しています。今回新たにAzure ADとShibboleth IdPを連携させるモジュールを開発し、それを核にしたサービス提供を開始。特長や導入メリットについて開発担当者に聞きました。
-

製品・サービス2019年2月 7日
「大塚商会実践ソリューションフェア2019」にサイオステクノロジーの複合機ソリューションが出展
「ITで開く、働き方改革。」をメインテーマに掲げた「大塚商会実践ソリューションフェア2019」に、今年もサイオステクノロジーの複合機ソリューション各種を出展いたしました。東京会場初日の模様をレポートします。
-
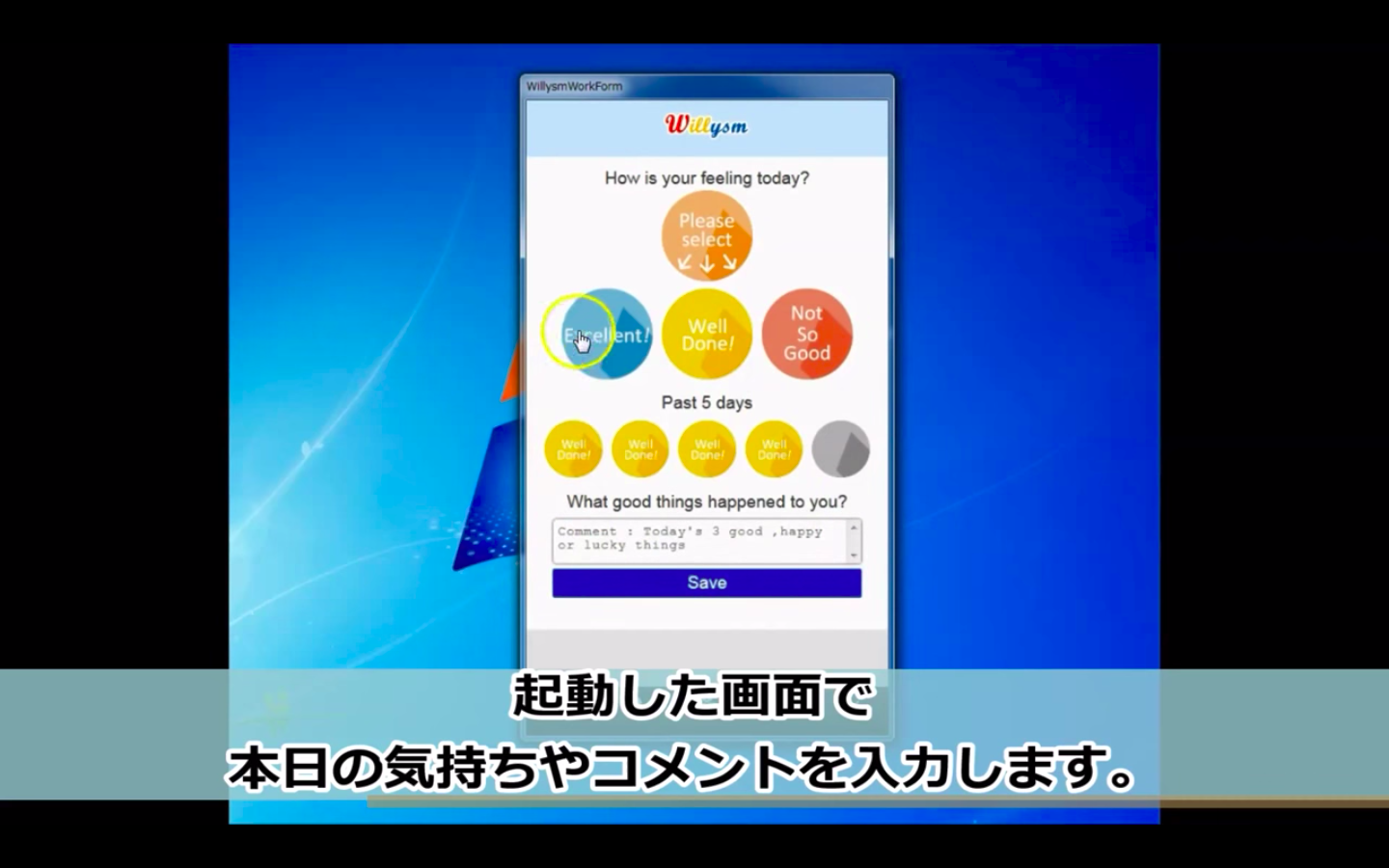
製品・サービス2019年2月 4日
三浦市社会福祉協議会 第3回「Willysm(ウィリズム)」利用者表彰式
神奈川県三浦市の社会福祉協議会は、モチベーション・マネジメントシステム 「Willysm(ウィリズム)」を活用した健康経営を実践しています。同協議会が2019年1月11日に開催したイベントで表彰された「Willysm」利用優秀者の方に職場での取り組みを伺いました。
-

カルチャー2019年1月31日
特集:サイオスグループでの多様な働き方──#04福岡・東京・富山・カリフォルニアをつなぐコラボレーション
多様な働き方を実現するために制度や環境の整備に取り組むサイオスグループ。時短勤務制度や産休・育休制度、リモートワークなどを活用して、多様な働き方を実践している社員を紹介するシリーズ企画。第4回は、多拠点間を結んで、プロジェクトを推進しているケースを紹介します。
-

カルチャー2019年1月23日
特集:サイオスグループでの多様な働き方──#03時短勤務とリモートワークを組み合わせて、子育て真っ最中
多様な働き方を実現するために制度や環境の整備に取り組むサイオスグループ。時短勤務制度や産休・育休制度、リモートワークなどを活用して、多様な働き方を実践している社員を紹介するシリーズ企画。第3回は、あえて時短勤務を選び、子育てを続ける女性を紹介します。
-

カルチャー2019年1月15日
特集:サイオスグループでの多様な働き方──#02出産を機に、完全在宅勤務へ
多様な働き方を実現するために制度や環境の整備に取り組むサイオスグループ。時短勤務制度や産休・育休制度、リモートワークなどを活用して、多様な働き方を実践している社員を紹介するシリーズ企画。第2回では、子育てとキャリア継続を両立する女性を紹介します。
-

カルチャー2019年1月 8日
特集:サイオスグループでの多様な働き方──#01 地方在住でリモートによる在宅勤務
多様な働き方を実現するために制度や環境の整備に取り組むサイオスグループ。時短勤務制度や産休・育休制度、リモートワークなどを活用して、多様な働き方を実践している社員を紹介するシリーズ企画。第1回は、サイオスグループにおけるリモートワーク制度の基となったケースを紹介します。
-

テクノロジー2018年12月 6日
Japan Container Days v18.12にてサイオステクノロジーが講演&出展
コンテナ活用とクラウドネイティブの最新動向がつかめる開発者のためのイベント「Japan Container Days v18.12」。サイオステクノロジーはスポンサーとして関わり、NGINX, Inc. Japan とともに講演とブース展示を行いました。
-

ピープル2018年10月25日
新戦力が追加され、パワーアップした発信力。オープンソース業界で、サイオスの存在感を強く押し出す!
多彩なサイオスグループの部署やチームを紹介するシリーズ企画の最終回。今回は、サイオステクノロジー株式会社の研究開発本部 研究開発2部を紹介します。
-

ピープル2018年9月25日
豊富な実績と高いプロフェッショナル意識を持った集団。最新のテクノロジーを追い求め ユニークな認証基盤構築の力をさらに高めていく
多彩なサイオスグループの部署やチームを紹介するシリーズ企画第8弾。今回は、サイオステクノロジー株式会社の第2事業部 技術1部を紹介します。
-

テクノロジー2018年8月27日
SIOS Open Source Conference 2018 エグゼクティブレセプションを開催
2018年7月27日、SIOS Open Source Conference 2018エグゼクティブカンファレンスが東京・GINZA SIX内のレストランTHE GRAND47にて開催されました。OSSを活用している企業のエグゼクティブクラスをお招きしたイベントの模様をお届けします。
-

カルチャー2018年7月23日
ビジネススタイルの多様性を推進する「働き方改革」の一環として、東京駅丸の内のコワーキングスペースを利用
サイオスグループでは、働き方の多様性を拡げるためにテレワーク/リモートワークを積極的に進めてきました。2018年3月から「WeWork東京丸の内北口」を契約して、試験運用を開始。作業場所やサテライトオフィスとしての役割にとどまらない、付加価値を生むワークスペースを訪ねました。
-

テクノロジー2018年7月 4日
忙しいあの人の居場所や状況を手軽にキャッチ。「Codyl Find」が日本のワークスタイルを変える!
サイオスの社内ベンチャー制度を利用して、2016年3月に誕生したソフトウェア開発会社コーディルテクノロジー。同社が2018年2月にリリースしたクラウドコミュニケーションツール「Codyl Find(コーディル ファインド)」の特長と開発の狙いを紹介します。
-
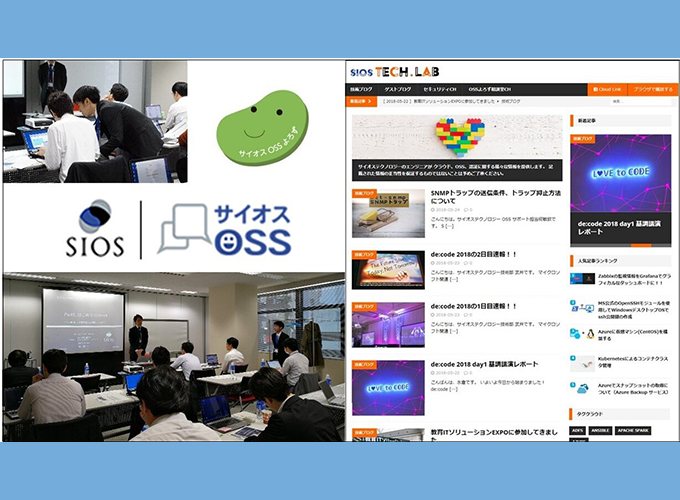
テクノロジー2018年5月31日
企業のOSS活用を力強く支援するサイオステクノロジーのサポートサービス 「OSSよろず相談室」の情報提供サービスがリニューアル!
Linux普及期より、企業向けのオープンソース・ソフトウェア(OSS)のサポートを実践してきたサイオステクノロジー。長年培ってきた技術力とナレッジを、サポートサービス「OSSよろず相談室」として提供しています。よりお客様のニーズに沿った情報を提供するため、そのサービスを拡充しました。
-

テクノロジー2018年4月16日
エピゲノム解析のスペシャリストとの協業で、未知の領域への挑戦を
サイオス、ならびにサイオステクノロジー は株式会社Rhelixa(レリクサ)と資本業務提携をおこない、共同でエピゲノムのクラウド解析プラットフォームを開発することを発表しました。その背景を掘り下げます。
-
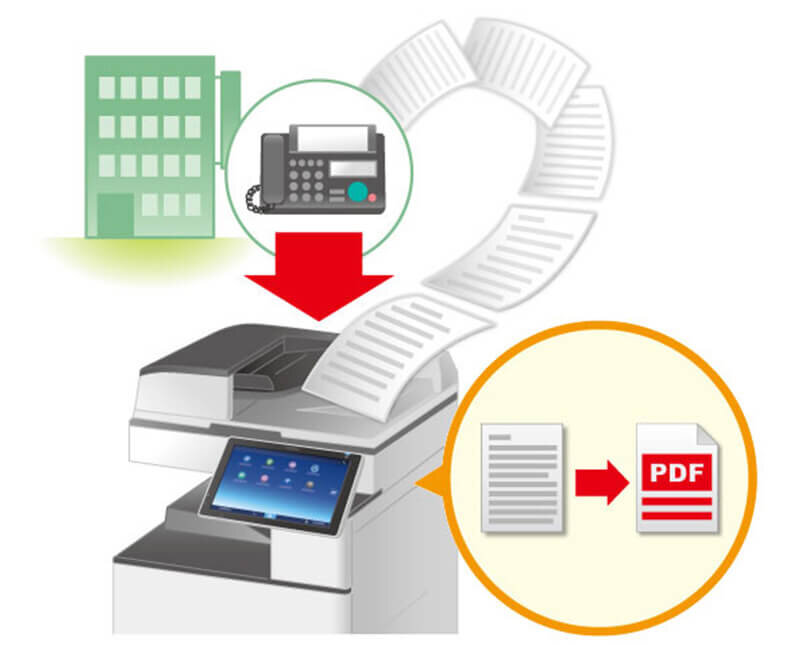
製品・サービス2018年3月27日
ファクス業務の煩雑さやリスクを手軽に解消!さまざまな現場で活躍する「Easyファクス」
2017年12月より提供を開始した複合機向けペーパーレスアプリケーション「Easyファクス」。おかげさまで多くの業界・業種の方々から引き合いをいただいています。今回は「Easyファクス」導入のメリットをいくつかの事例をもとに紹介します。
-

テクノロジー2018年3月 8日
SIOS Business Continuity & IT Summit 2018を開催
2018年2月23日、六本木アカデミーヒルズで開催された「SIOS Business Continuity & IT Summit 2018」。サイオステクノロジーはLifeKeeperなどの製品開発や提供を通じて、掲げるミッションをいかに実現していくのか――展望と戦略を発表しました。
-

テクノロジー2018年2月28日
情報システムへの不正アクセスが跡を断ちません。攻撃者はこの瞬間もさまざまな形で、企業のサーバーや個人のPCを狙っています。現状と対策を知っていただくため、サイオステクノロジーでは2018年2月7日に「セキュリティのトレンドを知って、正しい対策を!」と題するセミナーを開催しました。
-

製品・サービス2018年2月 9日
「大塚商会実践ソリューションフェア2018」にサイオステクノロジーの複合機ソリューションが出展
「ITで始まる。おしごと、まるごとグレードアップ。」をメインテーマに掲げた「大塚商会実践ソリューションフェア2018」に、今年もサイオステクノロジーの複合機ソリューション各種を出展いたしました。
-

製品・サービス2018年1月12日
三浦市社会福祉協議会 第2回「Willysm(ウィリズム)」利用者表彰式
三崎マグロで有名な三浦市の社会福祉協議会は、2016年4月にモチベーション・マネジメントシステム 「Willysm(ウィリズム)」を導入して利用促進を図り、健康経営を実践しています。このたび、昨年に続いて「Willysm」第2回の利用優秀者の表彰式が実施されました。
-

テクノロジー2017年12月21日
注目の自動化フレームワーク「Ansible」の普及と定着に、ライトウェル社と強力タッグを組む
運用管理・構成管理の自動化ツール「Ansible」。そのシンプルな構成やエージェントレスなどの特長で、注目度が増しています。インフラ構築や運用の現場で具体的にどのようなメリットが得られているのでしょうか。実務のエキスパートが意見を交わしました。
-

カルチャー2017年11月20日
サイオスのアイデンティティ──持株会社制移行により、グループの総合力を高める
2017年にサイオステクノロジー株式会社は創業20周年を迎え、10月1日にサイオスグループは持株会社制へ移行しました。多彩なサイオスグループを、どうまとめていくか? どんなグループ像を目指すのか? 社員に求めるものは? 代表取締役社長 喜多伸夫に聞きました。
-

製品・サービス2017年10月12日
HRサミット2017にて「Willysm(ウィリズム)」の講演を実施
2017年9月19日(火)、赤坂インターシティコンファレンスセンター(東京・港区)にて開催された日本最大級の人事フォーラム「HRサミット 2017」において、キーポート・ソリューションズの「Willysm(ウィリズム)」の講演がおこなわれました。
-

テクノロジー2017年8月 8日
APIエコノミーの実践「APIエコノミー友の会 V2」開催報告
好評を博す「APIエコノミー友の会」の第2回イベントが2017年7月5日、サイオス本社にて開催されました。APIの作成・管理・公開の全体像の解説とSwaggerによる実演、APIマネジメントプラットフォームKongのデモなど、実践的なセッションが繰り広げられました。
-

テクノロジー2017年8月 7日
茨城大学様では、学内のシングルサインオン環境を段階的に整備してきました。プロジェクトの中で鍵となったのはActiveDirectory、Office365、学認を利用する環境の認証連携でした。同大学IT基盤センターで伺った内容をこのたび冊子にまとめました。
-
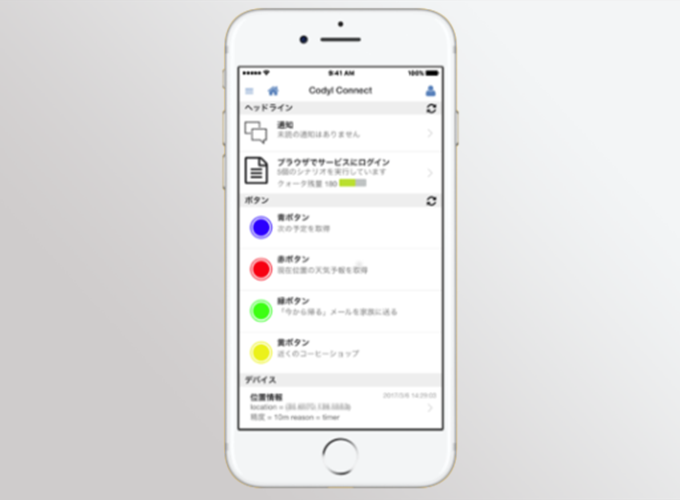
テクノロジー2017年8月 3日
さまざまなサービスやデバイスを自在につなぐ「Codyl Connect」とは
利用者の主体的なコントロールのもと、機械にできることは機械に任せ、賢く生活をする――。そんなコンセプトを実現する仕掛けづくりに取り組んでいるコーディルテクノロジー。サイオス社内の事業開発プロジェクトをルーツに持つ企業です。同社が提供する「Codyl Connect」の特長を紹介します。
-

テクノロジー2017年7月27日
サイオス OSSよろずユーザー会 SOY倶楽部総会 2017 を開催
発足から1周年となるサイオス OSSよろずユーザー会 SOY倶楽部。ご契約ユーザーをお迎えした第2回総会が開催されました。その概要をお伝えします。
-

ピープル2017年7月11日
【OSSのプロフェッショナルたち #4】サイオス「OSSよろず相談室」のテクニカルサポートエンジニアとして、お客様からの問い合わせへの的確な回答やお困りごとを解決するのが仕事という何敏欽(か びんきん)。日本に来たきっかけ、サポートチームの雰囲気、これからの目標などを尋ねました。
-

製品・サービス2017年6月14日
新しい仲間「コーティー」がデビュー ~ AWS Summit Tokyo 2017
サイオスに新たな仲間が増えました。クラウド上のシステム監視や自動復旧を実現する「SIOS Coati」のイメージキャラクター「コーティー」です。AWS Summit Tokyo 2017では来場者の皆さんと交流しました。#サイオスコーティー #awssummit
-

テクノロジー2017年6月 8日
HASコンソーシアムでの検証成果を報告 ~ EnterpriseDB Summit 2017 Tokyo
より高いHA(高可用性)を追求する「Higher Availability Solutions(HAS)コンソーシアム」。そこで実施されたLifeKeeperを活用した検証の成果がEnterpriseDB Summit 2017 Tokyoで報告されました。
-

ピープル2017年6月 6日
【OSSのプロフェッショナルたち #3】OSSを利用する企業から寄せられる問い合わせに対応するのが、サイオス OSSテクニカルサポートチームの多賀直希(たが なおき)です。業務で心掛けていること、多様な人々が織りなすOSSコミュニティの面白さを尋ねました。
-
.jpg)
テクノロジー2017年5月30日
2017年4月27日、レッドハット株式会社で「デジタル変革を実現するAPI活用の先端事例」セミナーが開催されました。サイオステクノロジー APIエコノミー推進部長 二瓶司が登壇し、APIエコシステムの海外事例とAPIマネジメント環境の導入ポイントを解説しました。
-

ピープル2017年5月23日
【OSSのプロフェッショナルたち #2】OSSの利用企業へのサポートや情報発信を手がける「サイオスOSSよろず相談室」。その企画・運営を担うOSS事業企画部の村田龍洋(むらた たつひろ)と、朴元哲(ぱく うぉんちょる)に、OSSの魅力や今後の夢を尋ねたインタビュー記事の後編です。
-

ピープル2017年5月18日
【OSSのプロフェッショナルたち #2】OSSを利用する企業へのサポートや情報発信を手がける「サイオスOSSよろず相談室」。その企画・運営を担当するOSS事業企画部の村田龍洋(むらた たつひろ)と、朴元哲(ぱく うぉんちょる)にOSSの魅力や今後の活動で目指すことを聞きました。
-

ピープル2017年4月26日
OSSとセキュリティのスペシャリストが考えるITインフラの未来〔後編〕
【OSSのプロフェッショナルたち #1】情報セキュリティの啓発に向けた情報発信などに努めるサイオス OSS&セキュリティエバンジェリストの面和毅(おも かずき)へのインタビュー記事の後編です。情報セキュリティに関わる組織の文化や個人の働き方、OSSコミュニティの今後などを話しました。
-
.png)
テクノロジー2017年4月25日
事例で学ぶAPIビジネス ~「APIエコノミー友の会」イベント開催報告
サイオスが創立メンバーに加わる「APIエコノミー友の会」では、APIから生まれる新しいビジネスの拡大やエコシステムづくりを目指して情報提供と情報交換の場を設けています。2017年4月4日には、サイオス本社にてキックオフとなる第1回目のイベントが開催されました。
-

ピープル2017年4月21日
OSSとセキュリティのスペシャリストが考えるITインフラの未来〔前編〕
【OSSのプロフェッショナルたち #1】IoTの普及とともに強まるセキュリティ上の懸念。CISSP(セキュリティ プロフェッショナル認定資格制度)の有資格者で、サイオス OSS&セキュリティエバンジェリストの面 和毅(おも かずき)に対応策を聞きました。
-

テクノロジー2017年3月27日
オープンソースカンファレンス 2017 Tokyo/Springで講演&出展
多彩なOSSコミュニティが参加する「オープンソースカンファレンス(OSC)2017 Tokyo/Spring」が3月10日〜11日、明星大学で開催されました。サイオスでは、マイクロサービスとOSSの情報セキュリティに関するセッションで講演しました。 #osc17tk
-

テクノロジー2017年3月16日
SIOS Coatiの特長とメカニズムを開発者が解説 #jawsdays
2017年3月11日、JAWS-UGが主催する「JAWS DAYS 2017」がTOC五反田メッセで開催されました。サイオスのランチセッションでは、パブリッククラウドにおける運用管理の負荷を軽減する「SIOS Coati」の仕組みや開発エピソードをお伝えしました。
-

製品・サービス2017年3月 7日
2017年2月23日、サイオスではLifeKeeper戦略説明会を東京ミッドタウンで開催しました。HAクラスターソフトウェア「LifeKeeper」を活用した事業継続(Business Continuity)分野での協業に向け、パートナー各社と方針を共有しました。
-

テクノロジー2017年2月22日
イノベーションを支えるオープンソース技術 ~OSS推進フォーラム2017開催報告
2017年2月15日、サイオス本社で開催された日本OSS推進フォーラム主催のセミナーでは、同フォーラムの1年間の活動成果が報告されました。また各部会メンバーがOSSの最新動向や注目技術を発表しました。
-

製品・サービス2017年2月21日
大塚商会「実践ソリューションフェア2017」Quickスキャン V4で複合機の可能性を広げる
メインテーマに「ITで育つ元気なオフィス。」を掲げた「大塚商会 実践ソリューションフェア2017」に、サイオステクノロジーの複合機アプリケーション「Quickスキャン V4」を搭載したリコー製最新複合機が出展されました。
-

テクノロジー2017年2月 8日
「Webサーバーログ解析サービス on Cloud」セミナー開催レポート
IoT時代のビジネスチャンスを拡大するのが、Webサーバーログ解析のソリューションです。2017年1月27日に東京ミッドタウンで開催した本セミナーでは、顧客接点であるWebサイトやアプリの分析・改善、プライベートDMP構築に関心を持つ参加者が多く詰めかけました。
-

製品・サービス2017年2月 3日
三浦市社会福祉協議会が「Willysm(ウィリズム)」の利用者表彰式を実施
三浦市社会福祉協議会は、2016年4月にキーポート・ソリューションズのモチベーション・マネジメントシステム 「Willysm(ウィリズム)」を導入して利用促進を図り、健康経営を実践しています。このたび、その利用優秀者の表彰式が実施されました。
-

ピープル2017年1月18日
「利用する人の立場になって開発すること」を心がけ、チーム全体で取り組む
【LifeKeeperのプロフェッショナルたち #4】HAクラスターソフト「LifeKeeper」を世の中に送り出す、サイオスのプロフェッショナルチームに迫るシリーズ。今回は製品開発チームの黒田将貴に、アジャイル開発手法を取り入れた現場でどのように仕事に向き合っているのか尋ねました。
-
